
Overview
This is a dataset of Japanese utterances spoken with different attitudes. This dataset contains 7199 Japanese utterances recorded from 16 speakers (8 females and 8 males). All the utterances have offensive linguistic contents and are labeled on four levels: joking (-1), neutral (0), serious (1), very serious (2). The labeling is the “perceived (by the labelers) attitude” of the speakers.
Description
We created the data set in two steps. First, we recorded utterances spoken with different attitudes by acting participants. Then, we labeled these utterances. Namely, the labels are not the attitudes intended by the speakers but the perceived attitudes labeled by the coders.
The utterances were recorded at the Advanced Telecommunication Research Institute International in Kyoto, Japan. We recruited 10 females and 10 males (avg. 37.3 years old, s.d. 15.2). The speakers were instructed to deliver a set of utterances while expressing the four following attitudes: joking, neutral, offensive and frenzied. The utterances were recorded in a quiet environment using a DPA 4060 headset microphone.
All the utterances had offensive linguistic contents such as “Koroshite yarouka! (I will kill you!)”, “Omae no nou ha sarunami da! (Your intelligence is like a monkey!)”, and “Shizukani shiro! (Shut up!)”.
Four speakers were not able to produce the desired attitudes and their utterances were removed. In addition, we removed any utterance that was corrupted by external noise.
Finally, we obtained 7199 segmented utterances from 8 females and 8 males.
We conducted the labeling with the four levels: joking (-1), neutral (0), serious (1), very serious (2). Three coders (l1, l2 and l3) were presented a few example utterances for each levels and labeled 10% of the data independently. We computed the quadratic weighted kappa [1] for the three pairs of coders and obtained 0.63, 0.63 and 0.66 meaning that there is a substantial agreement between the three coders. Consequently, only one coder labeled all the remaining utterances.
[1] J. R. Landis and G. G. Koch, “The measurement of observer agreement for categorical data.”, Biometrics, vol. 33 1, pp. 159–74, 1977.
examples:
- Joking
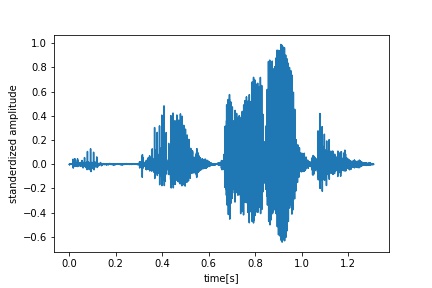
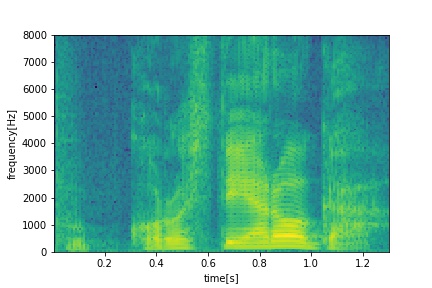
- Neutral
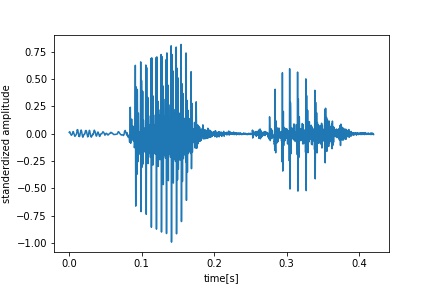
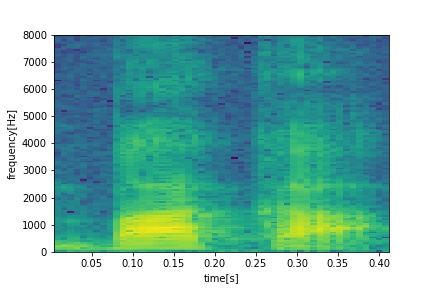
- Serious
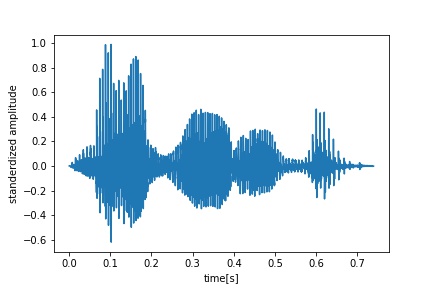
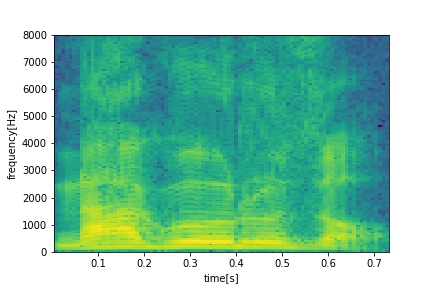
- Very serious
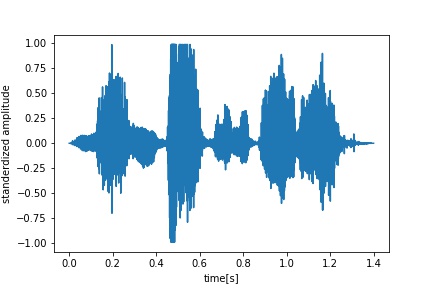
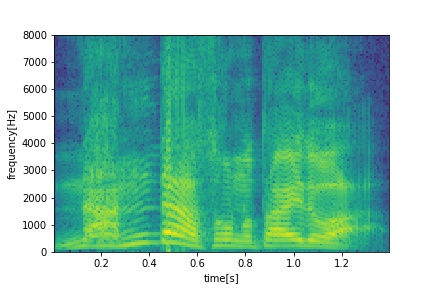
Samples & Labels
The dataset is organized as follows:
offensive_speech_dataset/
|
|- joke/ (wav & json files)
|
|- neutral/ (wav & json files)
|
|- serious/ (wav & json files)
|
|- very_serious/ (wav & json files)
There is one sub-folder for each level of perceived attitude.
In each sub-folder the audio samples are in wav format (1 channel, 16kHz, 16bit) and the label files are in json format . There is one label file for each audio file.
Ex:
F07-ne-124.wav F07-ne-124.json
The format of the file name is:
F07-ne-124.wav <speaker ID>-<intended attitude short name>-<utterance ID>.wav
Where
The speaker IDs are:
- F01, F02, F05, F06, F07, F08, F09, F10 for female speakers
- M01, M02, M03, M04, M05, M06, M07, M09 for male speakers
The intended attitude short names are:
- jo : Joking
- ne : Neutral
- of : Offensive
- fr : Frenzied
The utterance ID is an integer from 000 to 999. This number shows the rank of the utterance for a given speaker and an intended attitude.
The labels are in JSON format:
{
"labelers": {
"l1": {"joke_serious_level": -1},
"l2": {"joke_serious_level": 0},
"l3": {"joke_serious_level": -1}
}
}
10% of the dataset is labeled by coders l1, l2 and l3 and the remaining 90% is labeled by coder l1 only.
License
The dataset will be free to use for research purposes only. In case you use the data in your work please be sure to cite the reference paper below.
Reference
Kota Maehama, Jani Even, Carlos Ishi, Takayuki Kanda, “Enabling robots to distinguish between aggressive and joking attitudes”, in IEEE Robotics and Automation Letters, doi: 10.1109/LRA.2021.3102974, 2021.
Download link
To access the dataset, please contact us and we will send you a download link and the password. The size of the dataset is 216 MB.
Contact
even (at) robot.soc.i.kyoto-u.ac.jp